🚀 LLM Inference at Scale : High‑Throughput, Low‑Latency Architecture
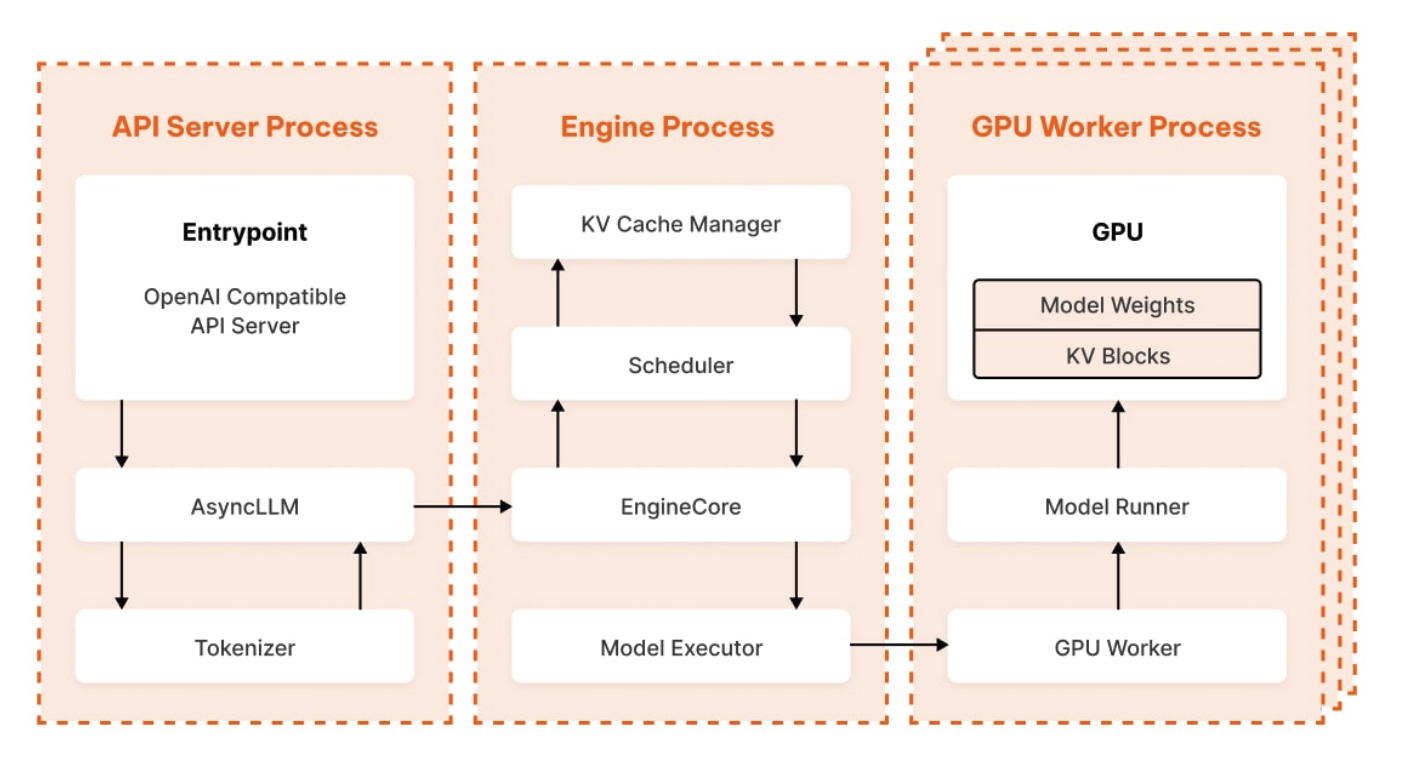
Junhao Li’s write‑up masterfully dissects vLLM V1’s architecture—from HTTP request to GPU matrix ops—revealing how smart batching and paged KV cache transform LLM serving. This isn’t just academic elegance; it’s a hardcore systems‑level play, marrying OS-style memory paging with GPU scheduling for win‑win efficiency. Contrasting with monolithic inference loops, vLLM’s modular flow (API → Async LLM → EngineCore → GPU → back) sidesteps Python’s Global Interpreter Lock (GIL) hits and scales predictably. For engineering teams building inference platforms, the punchline is clear: combine continuous batching, cache paging, and IPC-driven parallelism to crush latency and cost simultaneously.
Life of an Inference Request (vLLM V1): How LLMs Are Served Efficiently at Scale